
Here’s an excerpt from the piece on Tech Crunch that had everyone talking. “Imagine a future where individuals can illustrate their progression of lifelong learning and training and its links to their real-world performance. In this version of the future, the once-ubiquitous résumé has been ousted by the experience graph.” Read The Full Article
Library
The Web’s Evolution from the Social Graph to Learning Graph
Google Knowledge Graph
First the web was a platform to help manage networks of documents and webpage files. Then the web evolved into a platform to help us manage our social networks. Today we see the web maturing into a serious platform for lifelong learning to help us better understand the world around us.
Among the more radical (and plausible) scenarios for the future of lifelong learning is that our daily life experiences become reshaped by a learning graph that serves as visualized data record of what we know, how well we know it, where and who we learned it from and what we are trying to learn more about.
News organization could adapt their content with our learning graph to make us more informed. Celebrity chefs might access our learning graph and deliver new experiences to teach us more about food. Libraries might make book and course recommendations based on subjects that motivate us to learn more. Work training programs might tap into our learning graphs to make sure our skills stay relevant and can be tied to real world business challenges.
The most idealized, techno-optimistic vision is a world where people become less focused on consuming and more demanding for experiences that support a lifetime of learning. On the flip side, it does not take too much effort to imagine – or focus only on a dystopian future of learning graph abuse.
Today our social graphs shape our daily interactions with people, organizations and information flows. The next phase of our web-influenced culture will be teaching people the risks, rewards and responsibilities of managing a personal learning graph.
Bringing this vision of a learning graph influenced world will require us to go through the same transition as we saw with social norms confronting the era of social graphs. At first people will likely be confused, indifferent or threatened by the very idea of knowing more about what they know. Then we’ll enter a phase where people can say ‘how did we ever live without it’.
When Social Seemed Confusing and Creepy
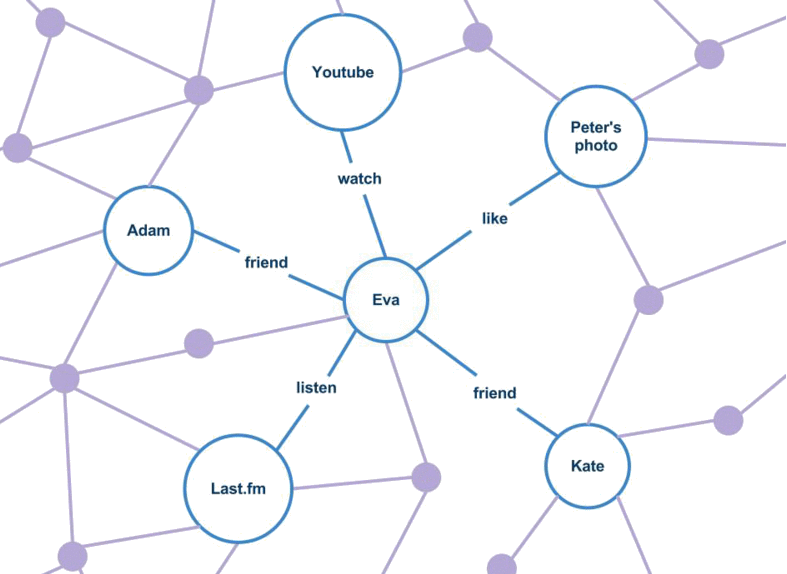 Think way back to 2004 when the idea of a ‘social graph’ impacting our daily lives seemed like a confusing and creepy concept. The early social graphs attempted to understand who I know and how I know them?
Think way back to 2004 when the idea of a ‘social graph’ impacting our daily lives seemed like a confusing and creepy concept. The early social graphs attempted to understand who I know and how I know them?
The information was structured in graph databases that are visualized by circles and lines. Circle nodes (e.g. people, concepts, places, resources) and lines that reveal relationships or types (e.g. is a friend, is a co-worker, ‘likes’). Unlike traditional ‘row and column’ databases, graph databases are perfect for data+information that is rich in connections and relationships.
Ten years ago, nobody was begging for a social graph. No organization thought about packaging its content to be compatible with social graph databases. There were no algorithmic ‘bots’ designed to scrape social network data for sentiment and behavior.
Today, hundreds of millions of people across the world cannot get through a day without tapping their social graphs in Facebook, Twitter, LinkedIn, Match.com or some other equal.
Social graphs, for better and worse, influence the thoughts and stories we share and the content we receive. Social graph databases are behind everything from crowd funding Kickstarter projects, Twitter ‘hash tag’ activism, to helping us find a new job or life partner.
All of this is possible because the social data is structured in graph databases made up of circles (nodes) and lines (edges) that make it easier to find connections, understand relationships and identify the right pathways to reaching a goal.
How about the learning graph?
Welcome to the (very) early days of the Learning Graph.
The learning graph is a visualized data record of what we know (which concepts and domains have we explored), how well we know it (where are we along the path of mastery), and where and who we learned it from (connection to people and resource collections). It might also include hints of what we are trying to learn more about.
Today the learning graph is only an idea. It is an idea with several names (e.g. Learning Record Store; Adaptive Learning Platforms) and potential ally technical specifications (e.g. ExperienceAPI, Mozilla Open Badges)
Yet it is a logical and plausible evolution based on today’s current direction of change in this networked society.
Here is a short list of assumptions to explore and learn more about.
#1 Graph Databases Play a Big Role
Learning is about making connections between things. It is about understanding relationships and abstractions. How we structure data-information will matter.
The category of ‘graph databases’ (e.g. Neo4j, Titan) offers the most appealing foundation to integrating web content into a world of personal learning graphs. The more content is structured around relationships, the more likely they will fit into the ecosystem of learning graphs.
Graph data-what?!
Think circles and lines! Circle nodes (e.g. people, concepts, places, resources) and lines that reveal relationships or types.
The circle (node) of Pablo Picasso would have a line connected (type of art movement) to another circle node of Cubism Art Movement. From the Cubism Art Movement circle you would find many other lines to other artists from the movement.
The future of learning has more to do with our we structure our data than any devices that we use to learn.
Instead of ‘writing books’ or developing learning material content in simple text or video form, we might see all content providers structuring information in graph format so that they have more seamless integration with other connected database frameworks.
#2 Learning Graphs will Stumble if We Limit Implementation to ‘Schools’
Technology-led solutions for school-based learning always seem to run into challenges and constraints that limit the effectiveness of the tool.
A more desirable path for the learning graph might be found in lifelong learning that occurs via self-direct experiences, social learning communities or with civic institutions like libraries, museums and arts organizations.
Instead imagine focusing on lifelong learning. Empowering likely early adopters like young people with learning graph experiences that simply capture their passion for learning – not taking a high stakes test.
Imagine a teenager inspired to learn more about street art. Their learning graph might contain location of where they encountered a particular artist. The graph might include the names of well-known artists and the connections between them in terms or style or cities. The graph might include links to widely read books, blogs or Twitter feeds. The graph might include connections of street artists to other art genres and artists that proceeded this movement. The graph might include connections to social, cultural or political themes explored by artists.
In this visualized experience the teenager can jump from concept to concept – and at surface level realize the relationships between concepts, people and resources. They can see at a glance how much there is to learn vs the concepts that they have attempted to learn about.
#3 Privacy & Data Ownership will be an Issue
Digital Data. Privacy.
We know this story well. Our digital lives have turned individuals into personal data factories. Organizations (public-private sector) see enormous value in knowing more about our lives through access to personal data. The notion of ‘privacy’ is being challenged at all levels.
Social norms and legal frameworks have not caught up. This has not stopped the mainstream embrace of social graph experiences that go far beyond Facebook.
The way forward is to anticipate challenges and work to develop solutions.
Individuals working in the world of learning data and analytics are hoping to avoid a repeat of this missed opportunity to bring people and institutions up to speed on the risks, rewards and responsibilites of managing personal data that drives our lifelong learning.
There will likely be a push for ‘Own Your Own Data‘ policies around lifelong learning. There will also likely be a push for companies to ‘own your data’. There will be learning graph data leaks and break-ins.
It is impossible to predict how it will unfold. We cannot resolve this emerging issue. People will have to stand up for their right to own their learning data. Keep calm, Carry on.
Learn More….
Folks talking about learning graph – learning map related visions:
Danny Hillis – best known for a visual learning map (a concept likely built on top of a learning graph)
OSCON 2012
Danny Hillis, Applied Minds – 2012 talk
Jon Bischke (Twitter; LinkedIn; CEO of Entelo) –
The Learning Graph & Reputation Graph (He references an earlier post by Kirstin Winkler)
Learning Startup to Watch: Declara’s Vision of a Cognitive Graph
Declara is one of the most unique startups in the world of enterprise-scale learning platforms. The company has built an intelligent social learning system that is often referred to in the media as a combination of Google’s Knowledge Graph and Facebook’s Social Graph.
Declara’s vision is to create and leverage a Cognitive Graph that delivers neuroscience-inspired personalized learning based on the context of real-world experiences, intent, outcomes and social relationships.
The system aims to deliver content recommendations and facilitate the most appropriate social connections between learners across large organizations and social communities. The platform integrates the latest capabilities of artificial intelligence subdomains – machine-learning and deep-learning to scale-up predictive analytics and prescriptive learning experiences based on an individual’s intentions, capabilities and needs.
The company sees a very rich and untapped landscape of learning analytics that will benefit from neuroscience-based insights on learning experiences. The ‘adaptive’ and ‘intelligent’ labels simply mean that Declara’s infrastructure learns over time based on real-world interactions and outcomes.
Declara’s CEO Ramona Pierson (Twitter) has an amazing comeback life story and a brilliant mind that sees the convergence of neuro-cognitive science, intelligent social systems, semantic search, graph databases, et al. Co-Founder Nelson Gonzalez (LinkedIn; Twitter) brings a pragmatic and optimistic lens to learning analytics and the intersection of local cultural elements and semantic search.
Declara has a very clear scale-out oriented business model that targets large customers such as national government associations (e.g. Mexico’s SNTE, Australia’s CSE) and enterprises like Genetech. They picked a wonderful problem to solve. Declara is a startup to watch…!!
Learn More:
- Declara on Twitter
- Bloomberg article
- Business Week Interview Ramona Pierson Novemmber 2013
- Semantic Web blog post
Interesting links on cognitive graph:
- IBM is hiring an intern for Social Analytics and Cognitive Graph (umm!!);
- Nodus Labs Graph
- Garry’s tags on Machine-Learning; Deep-Learning; Graph; Adaptive; Watson
Videos
Ramona Pierson
Interview at 2014 Gigaom event
Ramona Pierson speaking
Nelson Gonzalez – 2010 brief interview – hopefully more Youtube clips will appear soon!
https://www.youtube.com/watch?v=xmjDVrz5X5g
From Apple’s Knowledge Navigator to Mindmeld: The Evolution of Personal Assistant
Expect Lab‘s Marsal Gavalda walks us through 26 minute video of techno-optimistic geek goodness by looking at present day enthusasiam for personal assistant technologies and some of the historical milestones that brought us here.
Why the enthusiasm in 2014? The Spike Jonze’s movie Her gets credit for popularizing the idea of a likeable and lovable personal assistant but the real source of optimism is just old fashion innovation from our learning curve. Artificial intelligence sub-domains of machine-learning and deep-learning (used for real-time understanding of natural language) are making steady progress. The past few years have given the world very positive advances around knowledge graphs for natural language, sentiment analysis of unstructured data, and anticipation oriented recommendation systems.
The next five years will bring hype and real hope for functional contextual search and conversation-based experiences that make personal assistant beyond 2020 likely and doable. I have waxed poetic about Expected Labs MindmeldAPI and have the same respect for companies like NextIt and Artificial Solutions (Indigo) who are creating the early market demand.
My highlights from his talk: min 2:20 Github workflow and productivity visualization]
https://www.youtube.com/watch?v=fKen7IkdAm0
** **
Marsal mentioned the Apple 1987 video of the Knowledge Navigator
https://www.youtube.com/watch?v=QRH8eimU_20
** **
Garry’s Tags: Personal Assistant;
Public Libraries and the Creepy Line Solutions to Shrinking the Word Gap
 Summary: Public Libraries are the best positioned civic institution to help improve early childhood literacy (reading and writing) with a focus on reducing the Word Gap – which refers to the estimated 30 million word differential experience of words heard from birth to 3 years old across a spectrum of affluent to poverty-stricken famlies. This smaller vocabulary coupled with other stress inducers of poverty can impede the healthy brain development in young children that is critical for a lifetime of learning. The challenge for libraries will be in confronting the range of possible creepy lines associated with scaling a technology-led, behavior change-focused effort needed to close the word gap and enable the positive development of young brains.
Summary: Public Libraries are the best positioned civic institution to help improve early childhood literacy (reading and writing) with a focus on reducing the Word Gap – which refers to the estimated 30 million word differential experience of words heard from birth to 3 years old across a spectrum of affluent to poverty-stricken famlies. This smaller vocabulary coupled with other stress inducers of poverty can impede the healthy brain development in young children that is critical for a lifetime of learning. The challenge for libraries will be in confronting the range of possible creepy lines associated with scaling a technology-led, behavior change-focused effort needed to close the word gap and enable the positive development of young brains.
30 Million Words?
The Word Gap term grew out of research by University of Kansas child psychologists Betty Hart and Todd Risley and a 1995 study which measured the differences in words heard by young children. (Details of Research here). The research was revisited in 2008 by LENA (short for Language ENvironmental Analysis) and essentially confirmed the findings that a typical gap that exists between lower and higher income families – from birth to 3 years old was estimated at 30 million words.
[Similiar word sensing assessments have been used in Autism screening.]
Why is the Word Gap a lever for the future?
Studies suggest that early literacy (reading-writing) is critical in brain development and social skills empowered by a greater ability to listen and communicate. The healthy development of young brains is critical to a lifetime of learning and active engagement.
Despite its significant conclusions, the research has failed to gain mainstream traction as a lens for bringing positive social change. It is a scientifically defensible human policy lever that remains far off the radar of most people. The relative low cost and return on investment (in financial or social capital) in the healthy development of young brains appeals to even the most bottom-line focused business leaders. Libraries could help to elevate the importance of early brain development through reading and face-to-face engagement.
As a trusted institution with tremendous staff knowledge and experience in early childhood experiences, public libraries are well positioned to make a case for helping families recognize the importance of word-based experiences for their children. Expectations need to be managed. Libraries cannot solve all the complex problems that underlie poverty, but they can help create the conditions for parents and communities to understand the connection between words heard and early brain development.
Making a case for new funds to public libraries would certainly invite controversy and push libraries to test the creepy line where technology creates amazing new capabilities that makes us feel uncomfortable around potential trade offs that challenge personal boundaries and social norms.
There are two creepy lines to consider:
The Creepy Lines of Hardware the Listens:
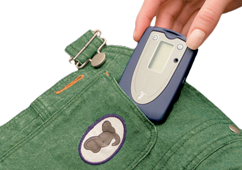
In 2013, Providence Rhode Island won Bloomberg Foundation’s Mayor Challenge to develop an early literacy engagement strategy that would help reduce the community word gap. The project included a plan to provide selected families with a portable device able to listen to the number of words heard by a child. Feedback data from the device would allow parents to know how well their child was progressing in hearing a targeted number of words each day, week, month and year.
These types of sensing and listening devices raise concerns of privacy. Namely, Are you going to record the conversations my child hears? Things that I say to my spouse?
The device, developed by Boulder, Colorado based LENA (Language ENvironmental Analysis) does not record words or conversations – rather it only listens to the number of words spoken to, or around the child. It can distinguish between words spoken by a human vs words coming from a television, computer or radio.
Yet the potential for abuse or misunderstanding will never disappear. We are in the early days of our physical technology being rooted in ‘sense and listen’ capabilities. Right now, the idea of having our phones listen to us – crosses the creepy line.
At the same time, it is important to recognize that we have already stepped into this strange future where the recording of web-based experiences and ebook-based behavior data is now readily available to publishers and software-device makers. (Read: The eBook is Reading You WSJ, 2012).
The question for parents focused on shrinking the word gap will be – Does crossing a creepy line to raise awareness of my child’s progress in hearing words – present more benefits than the potential risks and trade offs?
There is a creepy line associated with library collections that include devices and/or software programs that can sense the world around its patrons. Libraries might hold enough trust with patrons and communities to encourage this leap in embracing devices that listen (but do not record!)
The Creepy Lines of Changing Parenting Culture:
The second creepy line relates to how much libraries should shape culture and aim to change social norms of parenting and early childhood experiences. Some believe libraries should stay away from influencing social conditions – they believe it should be ‘just books’. Others see the role of libraries in creating an environment where anyone in a community can find the resources to thrive.
In reality, it has never been ‘just books’. In the United States, public libraries have played a role in shaping community culture for much of their history. Speak to older Americans from small towns and rural communities about their library experiences as a child and you are likely to hear about enriching moments that went far beyond checking out books. Before the post WWII era of larger government social service agencies it was public libraries who played a critical role in areas such as health, wellness and parenting.
There are many cultural assimilation challenges baked into the idea of helping parents become more self-aware of the vocabulary environment within their homes — and places where their children live. Research findings can be taken out of context or lead improper framing in the media where poor families are framed as bad parents when they are simply struggling to feed their families rather than focus on increasing the word count.
Libraries might possess the trust and open-door quality to parents — where they see an institution with programs and staff able to provide guidance and support as needed without the pressures that might come from a formal government agency or test-heavy school setting.
The intervention in parenthood also brings with it a sense of pedestal paternalism. Author Annie Murphy Paul captures the creepy line here in writing about the LENA device and Providene project:
“I find this completely fascinating, and also somewhat troubling. Recording parents’ speech to their children in order to show them that they are not talking to their children “enough” seems potentially rather intrusive and paternalistic.”
This is the essence of the creepy line– the fascinating capabilities of sensing technologies in changing outcomes are directly coupled with the need for more transparency and accountability. We can easily see this dynamic playing out beyond listening for word-count into the quantification. Companies and health insurance companies are testing the creepy line with quantified self or self-tracking programs for health and wellness.
Closing the word gap will require radical solutions. It is simply not enough to expect an education and awareness campaign to solve the problems. The use of listening devices and parent engagement will create new creepy lines that require use to talk about the trade-offs and all the risks, rewards and new responsibilities of this new era. The question for libraries will be how far do we step into the creepy zone
Learn More:
- NPR – 2013 story on Providence Reads
- In 2013 Bloomberg Philanthropies Mayors Challenge awarded Providence, RI for its Providence Reads project. The Project is using a recorder to measure the words (Developed by LENA)
- The Thirty Million Word Initiative (University of Chicago)
- Presentation by Dana Suskind (UChicago)
- Bridge the Word Gap – Website tracking the conversation and recordings from a 2013 conference
- LinkedIn Working Group – Bridge the World Gap
- PDF ‘Guide’ on Parenting and Word Gap
- Article Atlantic The 32 Million Word Gap
Companies such as You Tell Me Stories try to deliver parent solutions for improving early childhood reading and comprehension…
Video – a solid community level report on early literacy
Research
- The Early Catastrophe Report by Hart
- Rice University Word Gap
- Thirty Million Word Initiative
- LENA (short for Language ENvironmental Analysis) – Boulder, CO
- NPR Show on Word Gap
- Human Speechome Project
OYOD Own Your Own Data Movement
Summary: What type of data will make people want to protect it? Forget about social web data, personal health and lifelong learning data and analytics offer the most compelling niches to raise public awareness to own and control our personal data. Health data goes beyond clinical electronic health records (EHR) to include lifestyle analytics currently championed by the quantified self movement. Learning data goes far beyond high stakes test scores to include life-enriching experiences captured via the ExperienceAPI (TinCan) standard and controlled by the learner.
>> >>
Connected Data innovations for Health-Wellness & Lifelong Learning shape an experience industry
Where might the Own Your Own Data (OYOD) movement find its momentum?
The vision of an Own Your Own Data (OYOD) future is a world of informed and empowered individuals who can control their own personal data and leverage (via opt-in) it with companies, organizations and governments as they see fit.
Elevating data literacy and social norms on how to control, protect and apply our own personal data will take years to unfold. As of early 2014, the ‘OYOD movement’ is dispersed and off the radar. By the end of the year things could be very different. Projects such as IrisPact (pronounced I RESPECT) and media attention on personal data could shift expectations and set the stage for OYOD policies to be implemented.
Where might OYOD gain momentum? The near term target is tilting the balance of power over our social web data back to the user. Protecting personal data and advocating for ownership within social web environments is a worthy goal but late in the game to try and change the rules. Most existing social data projects are shallow efforts essentially linked to controlling our own precision advertising profiles.
If we are looking for arenas that an Own Your Own Data (OYOD) movement could emerge– healthcare and lifelong learning are two possibilities.
Health
The idea pushed within the healthcare and wellness space is broadly known as Personal Health Records or Electronic Health Records (EHR). These platforms allow individuals to gather, protect, share and synthesize individual and family health data records. It is an important transition but insufficient in understanding health-wellness issues beyond clinical setting. Lifestyle health analytics currently found within platforms and APIs from the quantified self community could compliment EHR records to give a more complete real-world picture.
Imagining a world with ‘ownership’ of personal health data is a complicated futures scenario, but plausible and certainly powerful enough to build popular support for ‘OYOD’ policies.
Health Data Projects to Watch:
BlueButton (US); OpenHealth Data (UK); SMARTPlatforms; Dossia; Patients Know Best; MyPHR; Indivio; Open EPIC; Kaiser Permanente Interchange, Atena CarePass, et al.
Learning
In recent years we built our ‘social graph’ that outlines who we know and how we know people by relationships. In the next decade many of us will build our own ‘learning graph’ of what we know and how we know concepts across a wide range of domains.
Building a data-driven ecosystem for controlling our learning graphs is complicated. It is never wise to try and place bets on data standards – but I am bullish on the long-term impact of two enabling foundations to record and leverage lifelong learning experience data.
The first concept to watch is: ExperienceAPI (or TinCanAPI) the next generation (post SCORM) standard application protocol of ‘activity statements’ (I did this…) that allow us to choose when we capture learning experiences. Learning activity statements can be online or offline – within school, work settings or walking in a park. (e.g. I read x-book. I attended x-workshop. I wrote y-book. I earned a masters degree from x-university. I watched x-TED talk. I visited x-museum exhibit. I took photographs of x-flowers. I read a NYTimes article on x-topic).
These ExperienceAPI statements are stored in a LRS (Learning Records Store) platform that gives individuals control over which “I did this…” life experience statements can be shared with other people, institutions or companies. Access to specific LRS data streams allows organizations to dynamically adjust information and experiences to individuals.
There are significant barriers to imagining an OYOD world of lifelong learning but there are paths forward which I will explore in future blog posts.
Learning Data Project to Watch:
ExperienceAPI (TinCanAPI), WatershedLRS, SaltboxWAX LRS;
Knowledge Graphs; Adaptive Learning Platforms
There are other angles to Lifelong Learning data. Adaptive learning platforms; and Danny Hillis’ vision of a Learning Graph
Image Use: Creative Commons URL
A Voice for Creative and Active Aging: Tim Carpenter [Video]
The future needs people like Tim Carpenter to elevate our expectations and positive thinking about the process of getting older. This shift towards a positive mindset on aging will be critical for investing in experiences and institutions that help older populations across our communities thrive. Carpenter is Founder of EngAGE and strong voice for active and creative aging.
TEDx SoCal: Thriving As We Age
Explore More
- Lifetime Arts – Libraries and Museums as centers for creative and active aging
More Tim Carpenter
- James Irvine Foundation – 2011 Leaderships Award-Video
An hour long presentation
Image Source: CreativeCommons
Future of Libraries – My Google Hangout with Eric Garland
A Google Hangout capture from a recent conversation I had with Eric Garland– colleague, friend and Host of the Garland Report. (Expect to see Eric interviewing others on a national TV network soon. A fun conversation!)
New Blog for 2014
I have let go of a few years of blogs posts from garrygolden.net from 2008-2013!
Time to start fresh. Old URLs may still be live but not linked here!